全体まとめページは↓より。

やりたいこと
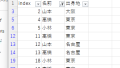
以下のような重複が多いデータに対し、特定の列について重複データを削除する。
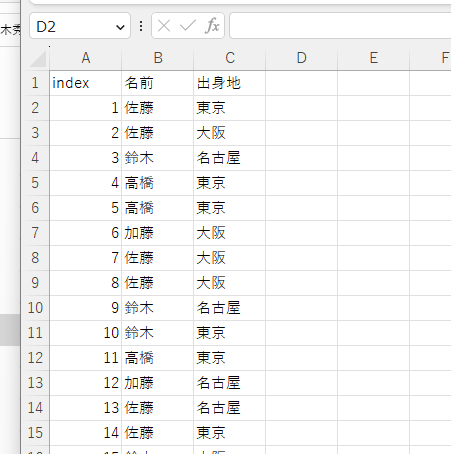
フォルダ構成
VSCodeで実行するときはprg配下を開いてpyファイルを作り実行する。
実装
★部分が今回のポイント。
辞書リストと同じ長さの転記フラグリストを定義する。(転記対象になる行は転記flg=1、そうでなければ転記flg=0)
辞書リストを重複削除したい項目でソートし、ソートリストをもとにキーブレイクで重複行の最初の行を判定する。
その行と対応する転記リストの行を、転記flg=1で上書きする。
転記処理の中に転記flgの判定を組み込み、転記flg=1になった場合のみ転記が実行されるようにする。
import os
import openpyxl
from operator import itemgetter
#辞書リストの作成関数
def make_shipment(sh):
shipment_list = []
for row in sh.iter_rows():
if row[0].row == 1:
header_cells = row
else:
row_dic = {}
for v, k in zip(header_cells, row):
row_dic[v.value] = k.value
shipment_list.append(row_dic)
return shipment_list
#項目リスト
collist = ["index","名前","出身地"]
#ファイル名を入力させる
print("ファイル名を入力:")
filename = input()
#読み込みファイルパスを作成
infile_path = os.path.join("..\indata" , filename)
#出力ファイルパスを作成
outfile_path = os.path.join("..\outdata" , filename)
#読み込みファイルからオブジェクトを生成
iwb = openpyxl.load_workbook(infile_path)
ish = iwb.active
#出力ファイルのオブジェクトを生成
owb = openpyxl.Workbook()
osh = owb.active
#辞書リストを作成
shipment_list = make_shipment(ish)
#★転記対象を管理するフラグリストを定義
flg_list = []
for n in range(len(shipment_list)):
flg_list.append(0)
#名前の重複削除
sorted_list = sorted(shipment_list, key=itemgetter("名前"))
old_key = ""
flg = 0
for dic in sorted_list:
if old_key == "":
old_key = dic["名前"] #最初のold_keyを格納する
flg_list[flg] = 1
if old_key != dic["名前"]:
old_key = dic["名前"]
flg_list[flg] = 1
flg += 1
#転記先ヘッダ処理
for col in range(len(collist)):
osh.cell(1,col+1).value = collist[col]
#転記先ヘッダ処理
for col in range(len(collist)):
osh.cell(1,col+1).value = collist[col]
#★転記処理
#転記flg==1ならその行を転記する。
flg= 0
list_row = 1
for dic in sorted_list:
if flg_list[flg] == 1:
list_row += 1
for col in range(len(collist)):
colname = collist[col]
osh.cell(list_row,col+1).value = dic[colname]
col += 1
flg += 1
#出力ファイルを保存
owb.save(outfile_path)出力結果
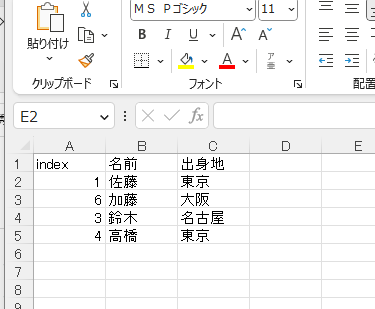
「名前」列を指定し、重複行が削除されている。
以上