全体まとめページは↓より。

やりたいこと
複数の列に対して抽出条件を適用してデータ抽出し、出力ファイルに転記する。
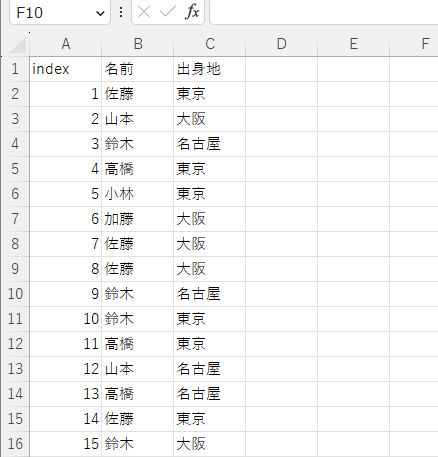
上記のようなデータに対し、
「名前」は”鈴木”,”山本”
「出身地」は”名古屋”,”大阪”を満たすデータのみ抽出したい。
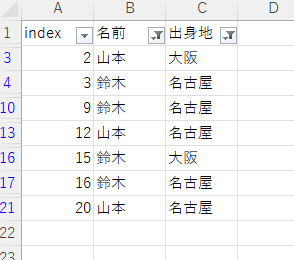
↓フィルターをかけるとこんな感じ。
ちなみに単一条件の場合は↓より。今回はこれをベースに複数列の場合の考え方を追加する。
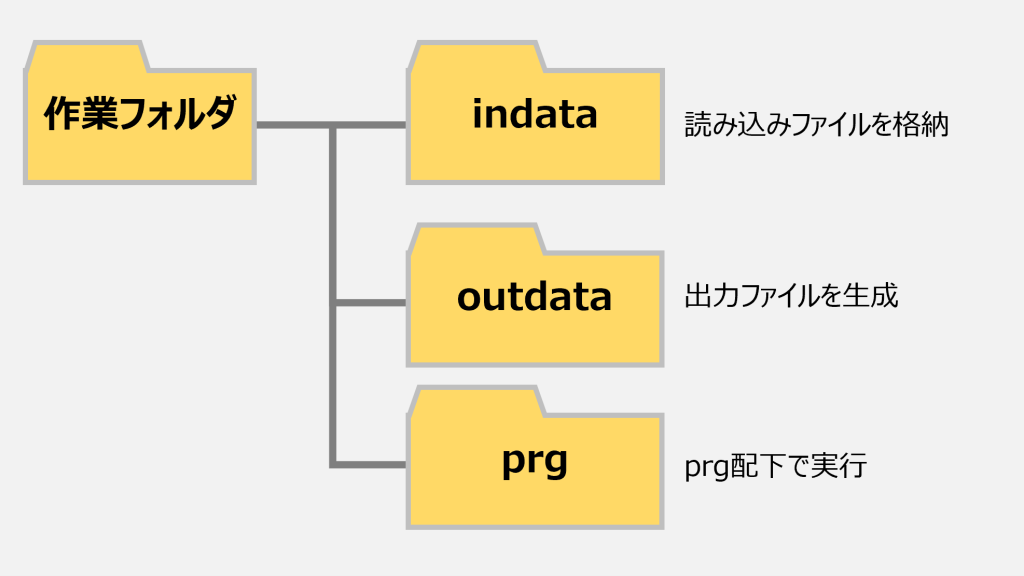
フォルダ構成
VSCodeで実行するときはprg配下を開いてpyファイルを作り実行する。
実装
★部分が今回のポイント。
抽出関数を定義する。元データの辞書データ、抽出リストと転記管理用の転記フラグリストを渡し、辞書リストを1行ごとに抽出リストと突合していく。もし抽出リストに合致する項目があれば転記対象として転記フラグ=1を設定し、これを全行に行ってから転記フラグリストを返す。
最初の抽出条件で抽出する場合と、2つ目以降の条件でOR条件にしたい場合はORモードで抽出関数を呼び出す。この場合、各行が条件に合致すれば無条件で転記フラグ=1を設定する。
一方で2つ目以降の条件でAND条件にしたい場合はANDモードで抽出関数を呼び出す。もともとの転記フラグリストのうち、転記フラグが1になっている行のみ抽出チェックの判定対象にする。
ここでANDモードのみの考え方としてチェックフラグを使用する。もし抽出リストに合致する項目があれば、その行のチェックフラグを1に設定する。
抽出リスト内のチェックが完了し、合致する項目が無かった場合(=チェックフラグが0のままの場合)は、転記フラグを0に戻す。この処理を全行に行い、結果的に転記フラグが1のままの行のみがAND条件を満たしている行として転記対象になる。
import os
import openpyxl
from operator import itemgetter
#辞書リストの作成関数
def make_shipment(sh):
shipment_list = []
for row in sh.iter_rows():
if row[0].row == 1:
header_cells = row
else:
row_dic = {}
for v, k in zip(header_cells, row):
row_dic[v.value] = k.value
shipment_list.append(row_dic)
return shipment_list
#★抽出関数
#引数
#1.mode: ORモードなら0,ANDモードなら1
#2.shipment_list: 辞書リスト
#3.flg_list: フラグリスト
#4.ext_list: 抽出条件のリスト
#5.colname: 抽出条件列
def ext_shipment(mode, shipment_list, flg_list, ext_list,colname):
if mode == 0: #ORモード
ext_key = ""
flg = 0
for dic in shipment_list:
ext_key = dic[colname]
for n in range(len(ext_list)):
if ext_key == ext_list[n]:
flg_list[flg] = 1
flg += 1
if mode == 1: #ANDモード
ext_key = ""
flg = 0
for dic in shipment_list:
flg_chk = 0
if flg_list[flg] == 1: #ANDなのでflg=1の行のみ処理対象にする
ext_key = dic[colname]
for n in range(len(ext_list)):
if ext_key == ext_list[n]:
flg_chk = 1 #抽出リストのうち、合致する項目があればchkフラグを1にする
if flg_chk == 0:
flg_list[flg] = 0 #chkフラグが0(合致する項目が無くANDにならない)の場合はflgを0に戻す
flg += 1
return flg_list
#項目リスト
collist = ["index","名前","出身地"]
#ファイル名を入力させる
print("ファイル名を入力:")
filename = input()
#読み込みファイルパスを作成
infile_path = os.path.join("..\indata" , filename)
#出力ファイルパスを作成
outfile_path = os.path.join("..\outdata" , filename)
#読み込みファイルからオブジェクトを生成
iwb = openpyxl.load_workbook(infile_path)
ish = iwb.active
#出力ファイルのオブジェクトを生成
owb = openpyxl.Workbook()
osh = owb.active
#辞書リストを作成
shipment_list = make_shipment(ish)
#転記対象を管理するフラグリストを定義
#ヘッダ行ははじめから転記対象:1を設定
flg_list = []
for n in range(len(shipment_list)):
flg_list.append(0)
#★抽出リストを作成
#「名前」と「出身地」がこれらの値に合致すれば転記対象列にする(AND)
ext_list_1 = ["鈴木","山本"]
ext_list_2 = ["名古屋","大阪"]
#★1つめの条件をORモードで呼び出す
flg_list = ext_shipment(0,shipment_list, flg_list, ext_list_1,"名前")
#★2つめの条件をANDモードで呼び出す
flg_list = ext_shipment(1,shipment_list, flg_list, ext_list_2,"出身地")
#転記先ヘッダ処理
for col in range(len(collist)):
osh.cell(1,col+1).value = collist[col]
#転記先ヘッダ処理
for col in range(len(collist)):
osh.cell(1,col+1).value = collist[col]
#★転記処理
#転記flg==1ならその行を転記する。
flg= 0
list_row = 1
for dic in shipment_list:
if flg_list[flg] == 1:
list_row += 1
for col in range(len(collist)):
colname = collist[col]
osh.cell(list_row,col+1).value = dic[colname]
col += 1
flg += 1
#出力ファイルを保存
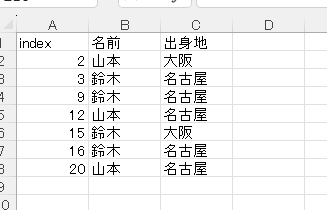
owb.save(outfile_path)出力結果
Excelでフィルターをかけた状態と同じデータが転記されている。
以上