やりたいこと
・あるDataFrameについて、特定の数値項目で上位25%の1群、それ以外の2群に分け、他の数値項目について1群と2群で有意差があるかを調べたい。
・新しいDataFrameを作成し、そこに項目名、t値とp値を格納して検定結果をわかりやすく参照したい。
実装
今回はsklearnで提供されているボストンの住宅価格のデータセットを使用し、住宅価格(MEDV)を上位25%の1群、それ以外の2群に分割してそれぞれの項目に有意差検定を行なっていく。
import pandas as pd
import numpy as np
import sklearn.datasets
import scipy.stats as statsボストンの住宅価格データを読み込み、DataFrameに成形する。
boston = sklearn.datasets.load_boston()
#データセットをDFに変換
df_x = pd.DataFrame(data = boston.data, columns=boston.feature_names)
df_y = pd.DataFrame(data = boston.target, columns=['MEDV'])
df = pd.concat([df_y,df_x], axis=1)
#df_y = pd.DataFrame(data = boston)
df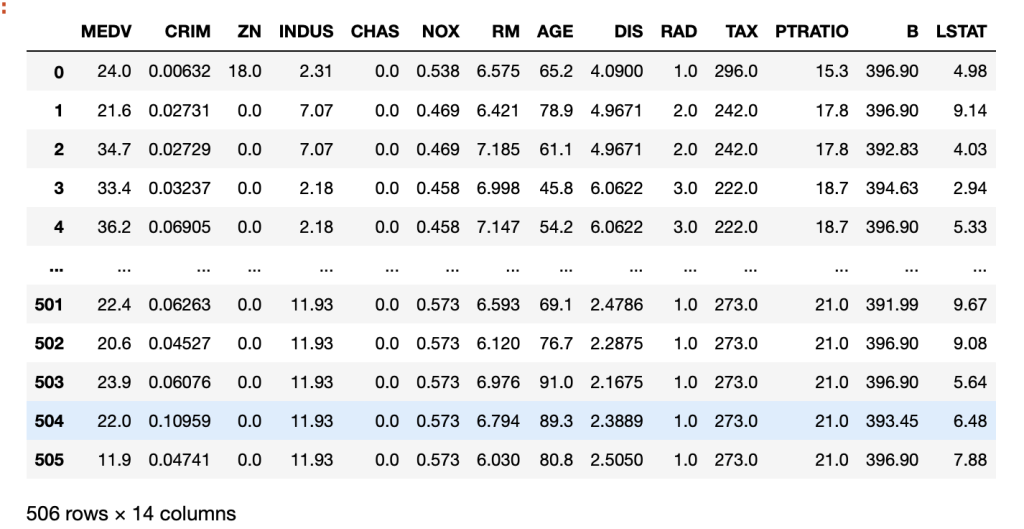
住宅価格MEDVを基準に、高価格上位25%の1群df_MEDV_25per、それ以外のdf_MEDV_otherに分割する。
#住宅価格MEDVで2群に分割する。
# df['MEDV']の上位25%の境界値を求める
threshold = df['MEDV'].quantile(0.75)
# 上位25%グループとそれ以外のグループに分割
df_MEDV_25per = df[df['MEDV'] >= threshold]
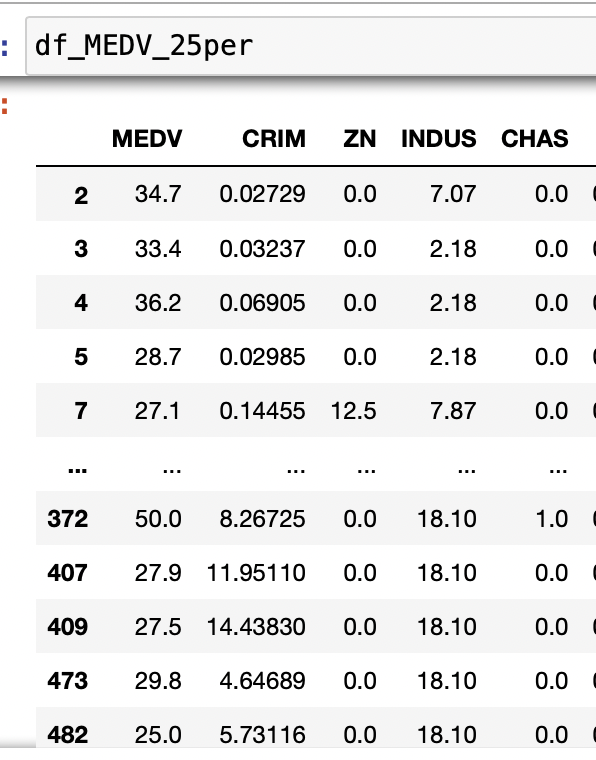
df_MEDV_other = df[df['MEDV'] < threshold]1群df_MEDV_25per。132行。
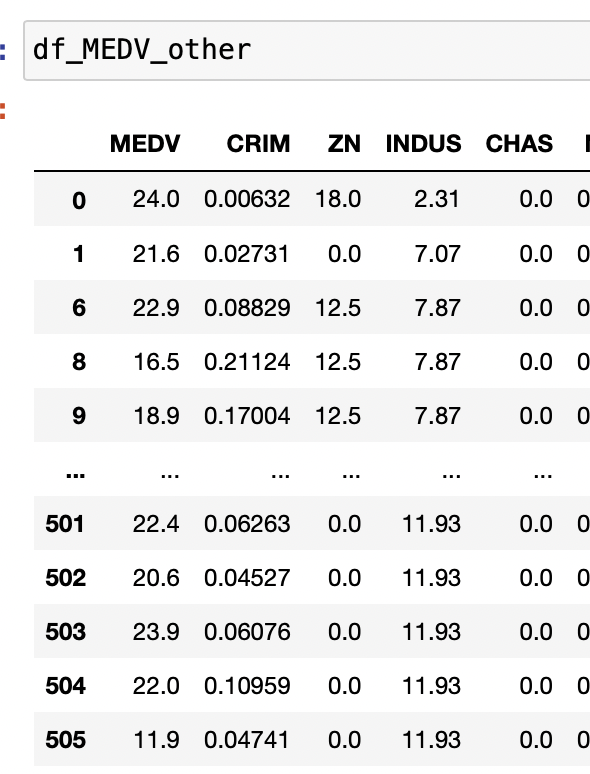
2群df_MEDV_other。374行。同値が多いため若干1群のレコードが多いが、おおむね25%で分割できている。
検定結果を格納するdfの作成、項目のチェック処理、検定の実行とそのループ処理。
# 検定結果を格納するdfを作成
df_ttest_result = pd.DataFrame(columns=["項目名", "t値", "p値"])
# dfA と dfB の列数が一致していることを確認
if df_MEDV_25per.shape[1] != df_MEDV_other.shape[1]:
raise ValueError("dfA と dfB の列数が一致しません")
# 各列に対して検定を行う
for column in df_MEDV_25per.columns:
# dfA[column] と dfB[column] の t 検定
t_stat, p_val = stats.ttest_ind(df_MEDV_25per[column], df_MEDV_other[column], equal_var=False) # Welchのt検定を使用
# 結果をdfCに追加
df_ttest_result = df_ttest_result.append({"項目名": column, "t値": t_stat, "p値": p_val}, ignore_index=True)
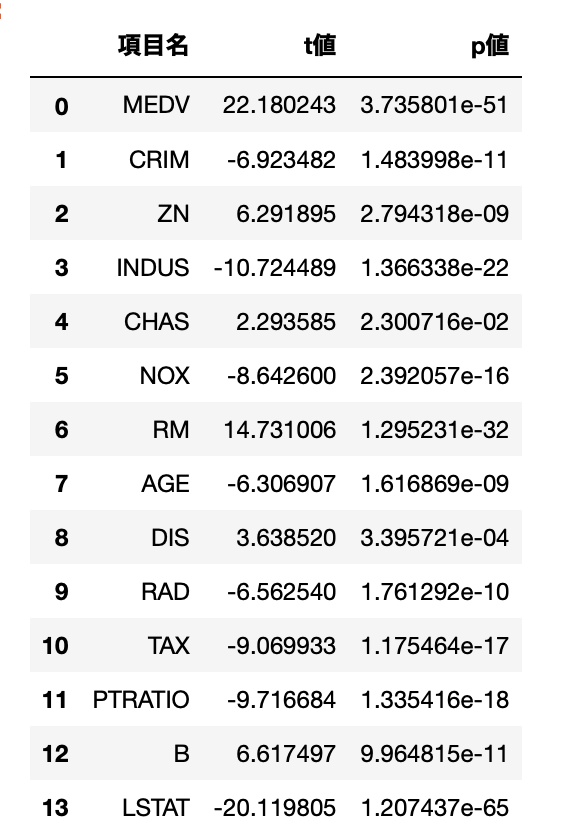
# 結果の表示
df_ttest_result検定結果。両側5%の検定で考えたとき、全ての項目で有意差があることを確認できた。
t値がプラスの項目は1群の方が大きい:広い家の割合、家あたりの平均部屋数など。
t値がマイナスの項目は2群の方が大きい:犯罪率、非小売業の割合、古い家の割合など。
以上